Określ problem oraz metodologię dla swojego benchmarku.
Przede wszystkim wypadałoby wybrać metodologię oraz określić charakterystykę problemu z jakim chcemy się zmierzyć. W jednym ze swoich poprzednich artykułów pisałem, że generalnie istnieją dwa „wymiary”, w których zazwyczaj mierzona jest wydajność aplikacji. A to, w którym „wymiarze” będziemy się poruszać zależeć będzie właśnie od tej aplikacji albo jeżeli chcielibyśmy być bardziej precyzyjni - od rodzaju obciążenia jakim charakteryzuje się ta aplikacja lub jej określony moduł (np. w aplikacji do obsługi poczty elektronicznej logi będą charakteryzowały się innym typem obciążenia i innym profilem IO, niż wewnętrzna baza danych). Jakie w takim razie są te wymiary? Do jednego z nich wrzucimy aplikacje, które charakteryzują się obciążeniami typu online (OLTP, systemy transakcyjne). Z kolei w drugim wymiarze znajdą się aplikacje i obciążenia typu wsadowego (DSS, strumienie audio/video, backup).
I tak, w przypadku tych pierwszych do analizy wydajności najczęściej bierzemy pod uwagę metryki związane z przepustowością (ilość operacji na sekundę IOPS i rozmiar transferu MB/s) oraz czasy odpowiedzi (ms). Tutaj ważne jest również, aby oczekiwane przez nas wyniki były osiągane przy niskim obciążeniu zasobów rozwiązania (procesorów, pamięci, dysków, portów, itp.) oraz charakteryzowały się możliwie krótkimi kolejkami. Kolejki w dowolnym miejscu naszego systemu wpływają negatywnie na czas odpowiedzi, a ten w tym przypadku chcielibyśmy utrzymać na jak najniższym poziomie.
Dla obciążeń typu wsadowego również istotne są metryki związane z przepustowością (ilość operacji na sekundę IOPS i rozmiar transferu MB/s). Natomiast w tym przypadku zależy nam na maksymalnym wykorzystaniu zasobów, aby mierzona przepustowość była jak najwyższa, a wartości kolejek umiarkowane. Duży poziom wykorzystania zasobów oraz dłuższe kolejki wpływają oczywiście negatywnie na czasy odpowiedzi (ms). W przypadku tej grupy aplikacji bardziej zależy nam jednak na tym, aby zakończyć określone przetwarzanie wsadowe w akceptowalnym oknie czasowym. Dlatego właśnie ważniejsze jest dla nas to, aby osiągnąć dużą przepustowość i w jak najkrótszym czasie „przepchnąć” jak największą ilość danych. A do tego potrzebujemy wykorzystać maksymalną ilość dostępnych w systemie zasobów.
Gdy popatrzymy teraz przez pryzmat powyższych definicji na wartości graniczne (threshold), widzimy, że obciążenia o charakterze online oraz obciążenia o charakterze wsadowym wzajemnie się wykluczają. Dlatego właśnie, ze względu na swój różny charakter, obciążenia te nie powinny współdzielić tych samych zasobów w tym samym czasie.
Co mierzyć i jak określić profil IO.
Typowe metryki, które wyróżniamy w profilu IO na przykład dla aplikacji typu online, to:
- ilość operacji na sekundę – I/O rate (IOPS),
- ilość operacji odczytu na sekundę – read rate (IOPS),
- ilość operacji zapisu na sekundę – write rate (IOPS),
- czas odpowiedzi dla operacji odczytu – read response time (ms),
- czas odpowiedzi dla operacji zapisu – write response time (ms).
Dla każdego z tych parametrów warto określić jakie wartości bazowe oraz jakie wartości graniczne są dla nas zadawalające. Pamiętajmy przy tym, że definiowanie wartości bazowych powinno się odbywać przy prawidłowo działającym systemie (dla normalnego stanu systemu). Na potrzeby wymiarowania nowego lub skalowania istniejącego systemu ważne jest określenie profilu IO dla interesującej nas aplikacji lub obciążenia.
Parametry profilu IO, które pomogą zwymiarować rozwiązanie we właściwym kierunku, to przede wszystkim:
- ilość operacji odczytu (%),
- ilość operacji zapisu (%),
- ilość operacji sekwencyjnych (%),
- rozmiar bloku dla operacji sekwencyjnych (kB),
- ilość operacji losowych (%),
- rozmiar bloku dla operacji losowych (kB),
- współczynnik trafień w cache przy zapisach i przy odczytach (%).
Ciekawym parametrem wydaje się być ten ostatni, dlatego zatrzymajmy się przy nim na chwilę. Przede wszystkim jest to parametr, którego wartość zależy od wykorzystywanej technologii (modelu macierzy dyskowej) oraz od rodzaju wykonywanego obciążenia. Najprościej mówiąc, wartość współczynnika trafień w cache dostarcza informacji o tym, jak często macierz odpowiada na zapytania bezpośrednio z jej pamięci cache versus jak często musi ona „sięgać” po dane do dysków twardych. Ponieważ producenci macierzy dyskowych, stosują w systemach operacyjnych tych urządzeń różne algorytmy „cache’owania” (i to, jakie to są algorytmy jest zazwyczaj jedną z największych tajemnic tych producentów), dlatego współczynnik trafień w cache nawet dla tego samego typu obciążenia może być inny w różnych macierzach dyskowych. Zależność pomiędzy wartością tego parametru, a potencjalną konfiguracją urządzenia, które spełni nasze oczekiwania wydajnościowe jest następująca:
- wyższa wartość współczynnika trafień w cache oznacza, że...
- częściej „czytamy z prędkością elektroniki” (bezpośrednio z pamięci cache, zamiast z dysków twardych), a to powoduje, że...
- potrzebujemy mniej wydajnego podsystemu dyskowego (np. mniejszej ilości dysków), aby osiągnąć oczekiwane poziomy wydajności.
Badanie poziomu wykorzystania zasobów (utylizacja).
Poziom wykorzystania zasobów urządzenia, będziemy mierzyć w inny sposób dla obciążenia wsadowego, a w inny dla aplikacji typu online:
- Dla aplikacji typu online bazujemy na wynikach minutowych (minuta-po-minucie). Wysoki poziom obciążenia w każdej badanej minucie powinien być powodem do zwrócenia uwagi na zaistniałą sytuację.
- Dla aplikacji typu wsadowego bazujemy na średnich wielkościach czasu, który nam pozostał do zakończenia okna przetwarzania. Tutaj wysoki poziom wykorzystania zasobów nie jest dla nas kłopotem. Ponieważ zależy nam na jak najszybszym zakończeniu się przetwarzania, dlatego chcemy wykorzystać zasoby urządzenia w maksymalnym stopniu. Maksymalne wykorzystanie zasobów ⇔ wysoka przepustowość ⇔ szybkie zakończenie procesu przetwarzania. Z kolei wysokie czasy odpowiedzi nie są tutaj traktowane jako problem. Są one naturalną konsekwencją wysokiej utylizacji zasobów oraz kolejek o umiarkowanej długości.
Wartość utylizacji pozwala pokazać w jakim procencie zasoby systemu są w danym momencie (lub średnio) wykorzystywane. Większość problemów związanych z wydajnością urządzeń jest związana właśnie ze zbyt dużą utylizacją jej poszczególnych komponentów:
- procesorów w kontrolerach – mierzymy poziom wykorzystania CPU,
- portów w kartach zewnętrznych – mierzymy poziom wykorzystania portów i mikroprocesorów, które obsługują te porty (w kartach IO),
- grup i pul dyskowych – mierzymy poziom wykorzystania grup dyskowych,
- pamięci cache – mierzymy wartość write pending (dane w pamięci cache, które czekają na zapisanie na dyskach; ten parametr mówi nam również dużo na temat pracy samego podsystemu dyskowego – czy został on dobrze zwymiarowany i czy radzi sobie on z „przyjmowaniem” danych z pamięci cache).
Konkretne wartości graniczne dla każdej z tych metryk będą zależały od typu komponentu macierzy, który monitorujemy, producenta tej macierzy oraz profilu aplikacji (wsadowa vs. online).
Na przykład dla obciążenia typu online utylizacja procesorów w kontrolerach nie powinna być większa niż 40% przy założeniu, że uwzględniamy również margines, który zostanie wykorzystany w przypadku wystąpienia awarii.
Gdy z kolei spoglądamy na wyniki utylizacji portów zewnętrznych, wysoki lub niski poziom wykorzystania mikroprocesorów, obsługujących te porty nie jest jednoznaczną wskazówką, określającą jaki jest poziom wykorzystania samego portu. Gdy utylizacja mikroprocesora portu zewnętrznego jest niska, wówczas powinniśmy dodatkowo zbadać przepustowość w MB/s, aby jednoznacznie określić, czy utylizacja samego portu jest również niska. Ograniczenia przepustowości w przypadku ruchu, charakteryzującego się małym blokiem I/O wynikają z kolei najczęściej z dużej utylizacji mikroprocesora, który obsługuje port zewnętrzny.
Wartości graniczne dla grup dyskowych w przypadku obciążenia typu online nie powinny być większe niż 50% w czasie prawidłowej pracy urządzenia. Z kolei dla obciążenia wsadowego utylizacja grup dyskowych powinna być tak duża jak to tylko możliwe, ponieważ w przypadku tego typu aplikacji z definicji zależy nam na osiągnięciu jak największej przepustowości, aby zakończyć proces przetwarzania w jak najkrótszym czasie. Wtedy spodziewane maksima dla grup dyskowych to 70-80% utylizacji.
W przypadku pamięci cache najczęściej posługujemy się parametrem write pending, który określa poziom wykorzystania pamięci cache (ile danych czeka w pamięci na zapisanie ich na dyski):
- wartość write pending do 30% uznaje się za poprawną pracę,
- częste pojawianie się wartości na granicy 40% powinno wzbudzić naszą uwagę,
- w przypadku poziomu 50% uwaga ta powinna być wzmożona,
- przy 70% często wymuszany jest proces „zrzucania” danych z pamięci cache na dyski (zależy to oczywiście od architektury macierzy oraz jej producenta).
Monitorowanie czasu odpowiedzi (response time).
Czas odpowiedzi zależy od wymagań aplikacji oraz od poziomu SLO (Service Level Objective) jaki sobie założymy lub jakiego się od nas wymaga dla utrzymania odpowiedniej jakości pracy aplikacji. Ponieważ na jakość pracy aplikacji bezpośredni wpływ będzie miał czas odpowiedzi wolumenu logicznego (LU), na którym ta aplikacja jest zainstalowana, to właśnie ten wskaźnik powinniśmy monitorować, aby móc wyznaczyć pojawiające się różnice wraz ze wzrostem obciążenia.
Projektowanie wydajności systemu.
Gdy projektujemy wydajność systemu, powinniśmy to zrobić zarówno dla scenariusza prawidłowej pracy urządzenia, jak i dla przypadku ewentualnych awarii. Dobrze jest przy tym zdefiniować:
- wartości punktów granicznych dla poszczególnych metryk,
- wartości brzegowe utylizacji systemu, w obrębie których jego praca będzie uznawana jako prawidłowa oraz dla których „zaświecą się” ostrzeżenia i alarmy.
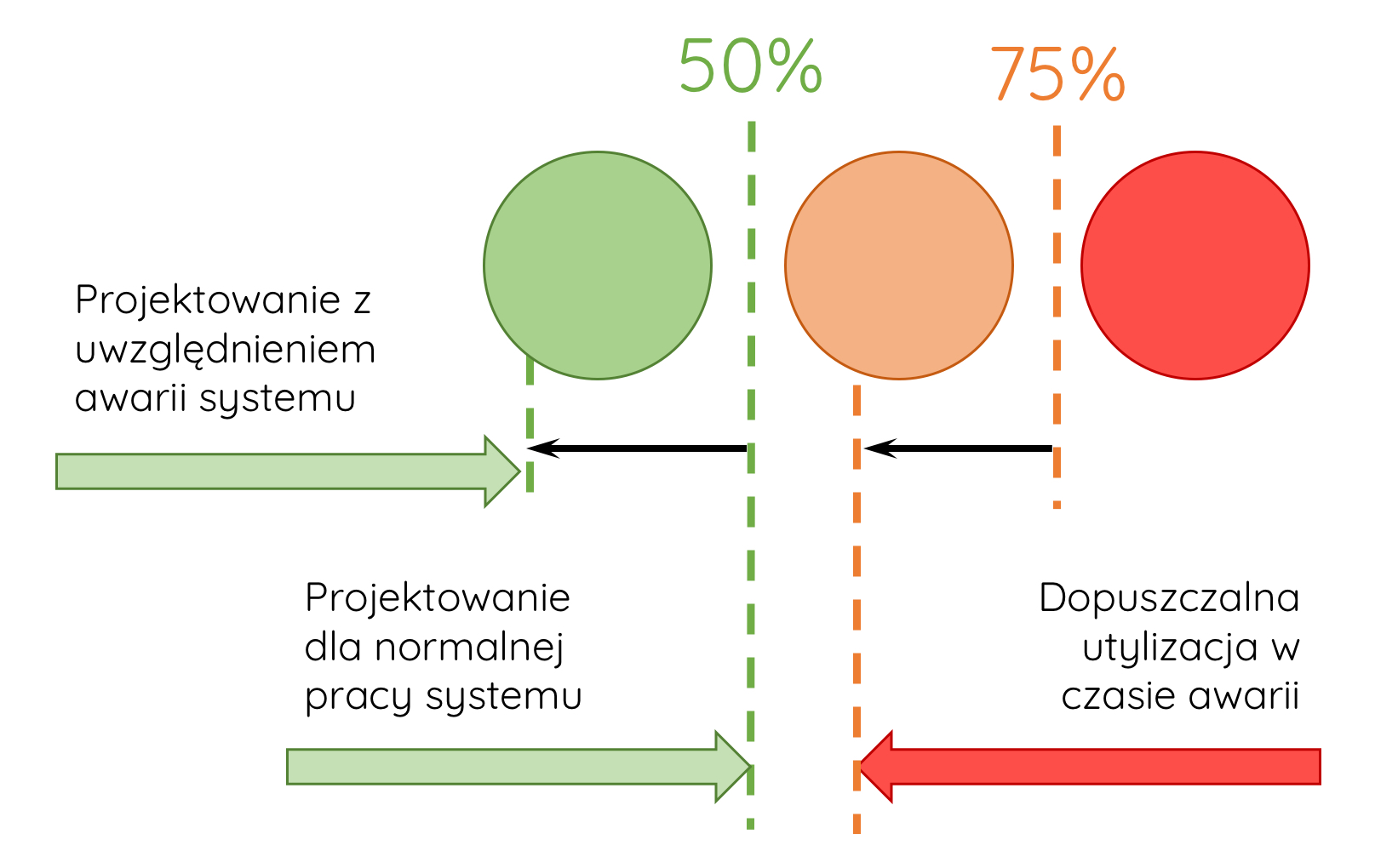
Zielony kolor na powyższym rysunku oznacza prawidłową pracę systemu. Żadne punkty graniczne nie zostały przekroczone. System charakteryzuje się zdolnością obsługi obciążenia bez zauważalnego wpływu na jakość pracy aplikacji.
Pomarańczowy kolor (ostrzeżenie) oznacza, że punkty graniczne dla określonych metryk są przekraczane od czasu do czasu. Warto zwrócić większą uwagę na te metryki podczas monitorowania pracy systemu. Znaczące zwiększenie obciążenia może wpłynąć na jakość pracy aplikacji.
Czerwony kolor (alarm) oznacza, że punkty graniczne są przekraczane regularnie. Należy przeanalizować działanie systemu, aby wykryć i wyeliminować zagrożenia. Dalsze obciążenie systemu może spowodować poważną degradację wydajności pracy aplikacji.
Raportowanie.
Większość problemów wydajnościowych jest analizowana przy użyciu 1-minutowych interwałów czasowych (1-minutowego próbkowania). Przypadki, w których używamy krótszych interwałów są bardzo rzadkie, ale również występują. Analiza wydajności z 1-minutowym interwałem jest na ogół ograniczona czasowo i trwa z reguły 1-2 dni. Wydłużanie tego okresu może powodować zbyt duże uśrednianie maksymalnych wyników monitorowanych metryk wydajnościowych, co na koniec skutkuje błędnym wynikiem analizy. Niektóre aplikacje do monitorowania i raportowania wydajności potrafią przechowywać wyniki z 1-minutowym próbkowaniem bez uśredniania tych próbek nawet przez okres jednego roku.
Mechanizmy, które pomagają „utrzymać w ryzach” wymagane wartości SLO.
Ich dostępność będzie oczywiście uzależniona od modelu urządzenia, które wykorzystujemy. A ponieważ nie zamierzam zamieniać tego artykułu w broszurę marketingową, dlatego poniżej wymienię jedynie kilka mechanizmów, na które warto moim zdaniem zwrócić uwagę. Technologie te mogą pomóc w utrzymaniu wymaganych wartości dla mierzonych parametrów wydajnościowych w trakcie codziennej pracy z systemem. A w przypadku, gdy pojawią się problemy z wydajnością (a te zawsze prędzej, czy później się pojawiają) ułatwiają namierzenie oraz szybkie wyeliminowanie wąskich gardeł.
- Mechanizmy QoS (Quality of Service), które pozwalają określić oczekiwane przez nas wartości parametrów wydajnościowych (IOPS, MB/s). Wartości te zazwyczaj możemy definiować dla różnych zasobów urządzenia:
- Dla portów zewnętrznych, gdy do tego samego portu podłączone są różne serwery. Określamy wartości IOPS i MB/s dla naszego krytycznego systemu (aplikacji), pozostałe aplikacje otrzymują „resztę” wolnych zasobów. W ten sposób możemy zagwarantować stabilny i przewidywalny poziom pracy naszej krytycznej aplikacji.
- Dla wolumenów logicznych, gdy wiele takich wolumenów z różnymi aplikacjami korzysta z tej samej grupy / puli dyskowej. Analogicznie jak powyżej określamy wartości IOPS i MB/s dla naszej krytycznej aplikacji lub ograniczamy wartość tych parametrów dla jej „sąsiadów”, którzy mogliby w negatywny sposób wpływać na jej pracę.
- Technologia logicznego partycjonowania zasobów, która pozwala na rozdzielenie aplikacji. Każda z aplikacji korzysta ze swoich zasobów bez negatywnego wpływu na pracę pozostałych.
- Realizowanie określonych funkcjonalności przez wyspecjalizowane układy. Odciążamy w ten sposób główne procesory urządzenia, które odpowiadają za obsługę i działanie systemu operacyjnego i poszczególnych jego funkcji.
- Mechanizmy monitorowania wydajności i szybkiego reagowania na pojawianie się wąskich gardeł:
- definicja poziomów granicznych dla tych parametrów wydajnościowych, których wartości mierzymy, aby mieć pewność, że wymagane przez biznes poziomy SLO są spełniane,
- dynamiczne dostosowywanie się tych poziomów granicznych do codziennego ruchu w naszym środowisku (rozróżnianie typowego ruchu od nieprawidłowych i niepożądanych wzrostów obciążenia),
- monitorowanie poziomów SLO oraz automatyczne reagowanie w sytuacji ich przekroczenia (np. automatyczne uruchomienie procesu, którego celem jest przeniesienie aplikacji na szybsze dyski, lub dostarczenie dla niej dodatkowych zasobów),
- korelacja zmian związanych z wydajnością ze zmianami konfiguracyjnymi systemu.
Gdzieś w dalszej perspektywie czasu (moim zdaniem, wcale nie aż tak bardzo odległej) można wyobrazić sobie tutaj również takie rozwiązania i systemy do monitorowania, które w oparciu o uczenie maszynowe będą przewidywać nadchodzące, bardzo wysokie obciążenie (peak) i proaktywnie wywoływać procesy, które wyeliminują potencjalne zagrożenie lub odizolują od niego aplikację.
Ale póki co wróćmy jeszcze na koniec do naszej dzisiejszej rzeczywistości…
Ku pamięci.
- Określ i zdefiniuj metryki, które będą dla Ciebie ważne, zanim zaczniesz monitorować wydajność systemu.
- Zidentyfikuj dane, które wykorzystasz podczas planowania wzrostów w zakresie pojemności i wydajności systemu.
- Projektuj system pod kątem jego wydajności, aby zagwarantować wymagania dla aplikacji typu online oraz typu wsadowego.
- Poznaj profil I/O aplikacji.
- Zidentyfikuj kluczowe obszary, które wymagają sprawdzenia i monitorowania podczas skalowania systemu.
- Korzystaj z mechanizmów i narzędzi, które na co dzień pozwolą Ci utrzymać i zagwarantować wymagane przez biznes i właścicieli aplikacji poziomy SLO.
Ważne. Operacja IO nie zaczyna się na porcie zewnętrznym macierzy dyskowej. Tam wcześniej dzieje się również bardzo dużo ciekawych rzeczy. Dlatego, aby mieć pełen obraz sytuacji warto monitorować wydajność na całej drodze IO (od aplikacji do dysku twardego). Idealnie, jeżeli dodatkowo jesteśmy w stanie zrobić to za pomocą jednego narzędzia.
Dodaj komentarz